Data Structures & Algorithms
Data Structures, what are they?
Arrays, queues, stacks, linked lists, hash maps, graphs, trees, heaps. These are all examples of data structures. To put it simply, data structures allow you to arrange and manipulate your data in an expected way. Programming languages will often abstract a lot of the code that makes these things work, and often for good reason, it would be a little tedious to have to programatically create commonly used data structures from scratch when usually as engineers we are only interested in using data structures as opposed to creating them.
That said, I think it is still really valuable to learn about how these data structures work at a lower level, for multiple reasons. Not only will you understand these data structures better when you go to use them in your applications, but you will have a better grasp of performance trade offs by knowing the time and space complexity of each one and their given exposed methods, and for better or worse, a lot of companies still expect decent knowledge on these data structures when it comes to interviews.
I’ll dive into one data structure now, a singly-linked list.
Singly-Linked List
Disclaimer: Please excuse my rudimentary drawings, I’m still getting used to the tool Procreate. Also, every circle in the below diagrams represents a node in the list.
Imagine you are standing alone in a field, someone comes to stand in front of you and turns around, you place your hands on their shoulders. Someone comes up to them and they do the same thing. This happens three more times. This is a singly-linked list, well, a human one. In computer speak, each person would normally be called a node, in this scenario you were the head node and the very last person with no one to place their hands on is the tail node. The pointer would be a reference to the next node, or null in the case of our tail node, in our example the arms represent the pointers.
Initially a linked list will not have any nodes, but for examples sake, here we have a single node with a value of 1. Nodes can and usually will contain values. Notice this node is both the head and tail node since it’s the sole node in the list. It also points to nothing, or null.

Here a second node is added, notice the first node is still the head node, but now the new node becomes the tail. In this example we are always adding to the end of the list, so the new node will always be the tail.
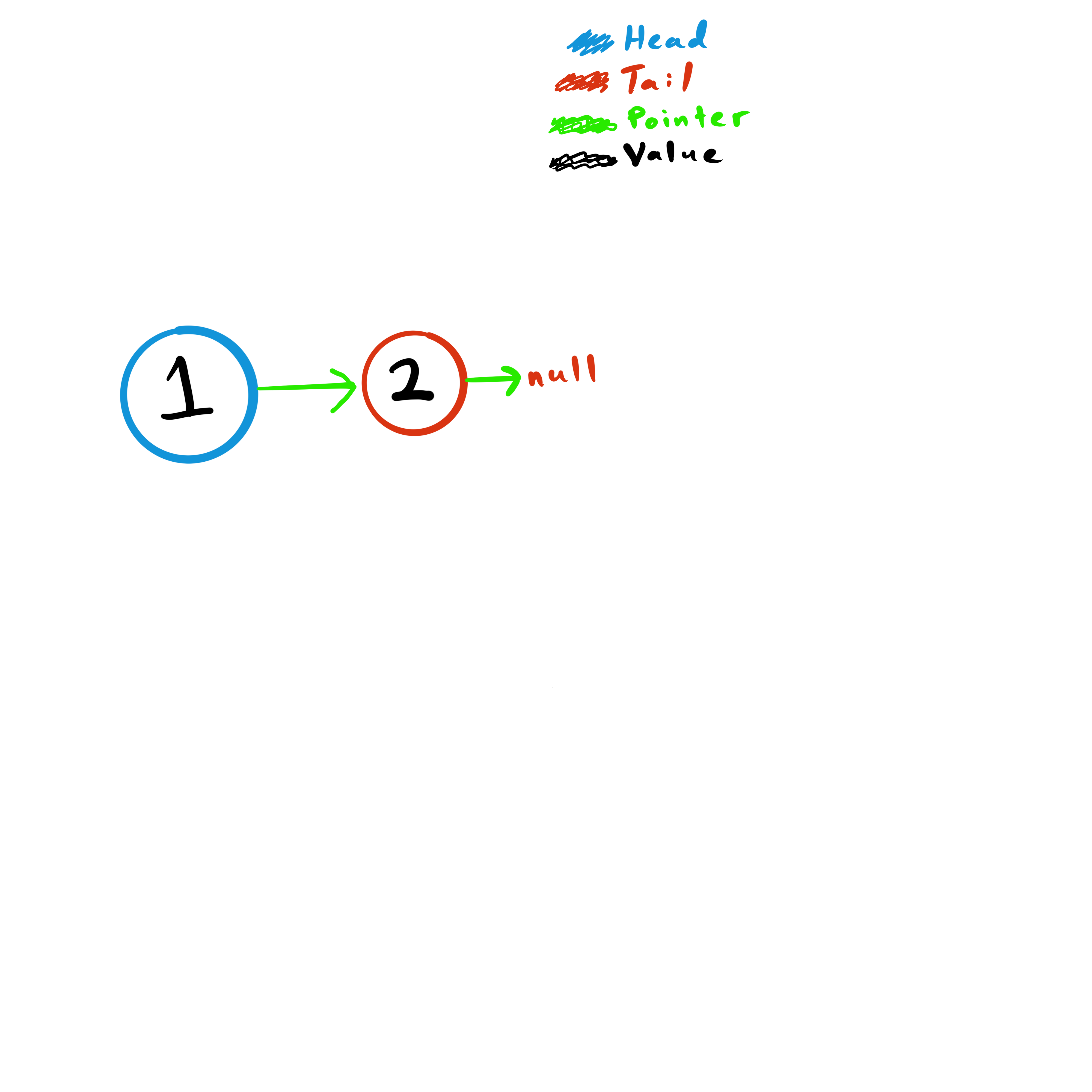
Here we add a third node which becomes the new tail and we finally have a node that is neither the head or the tail, just a node.
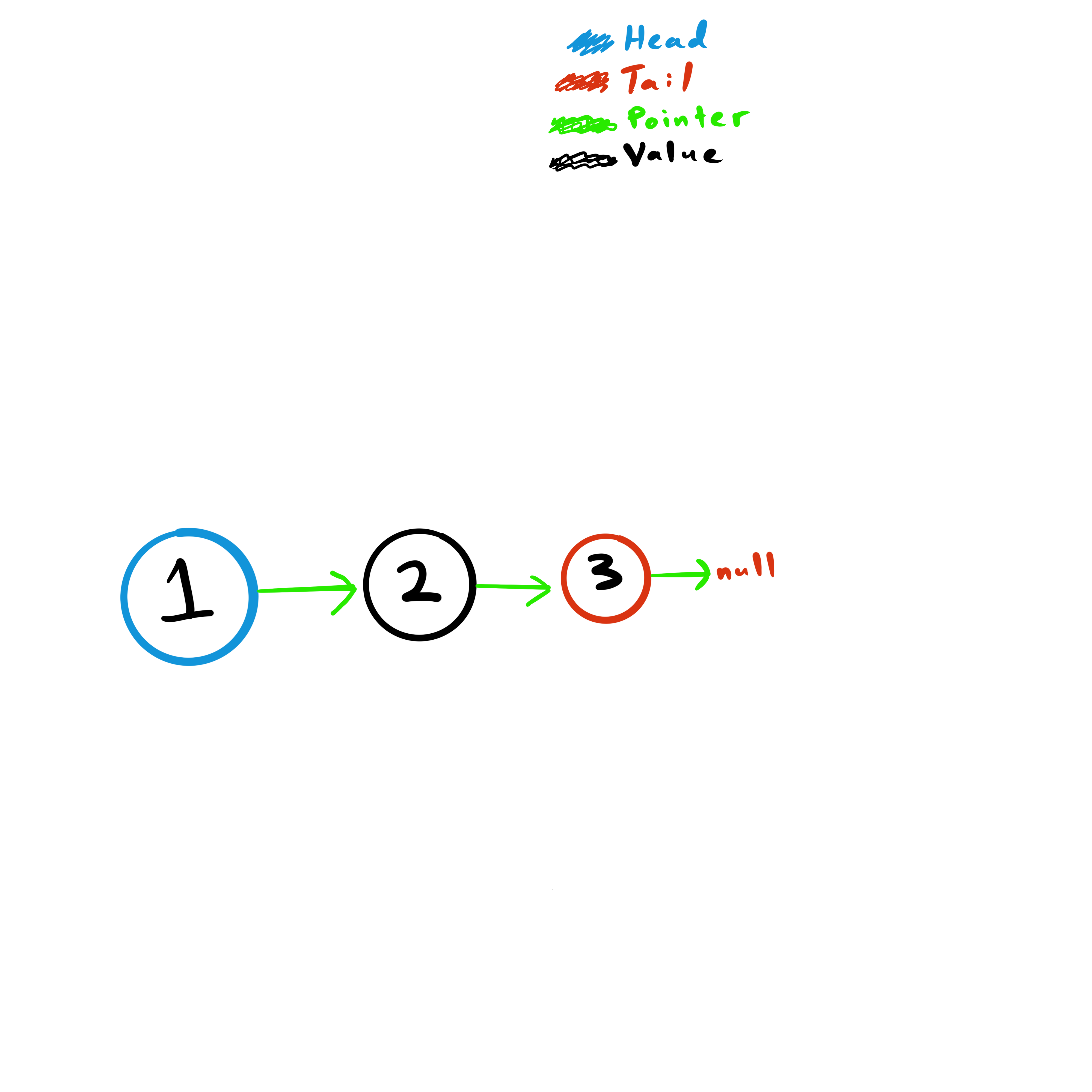
Adding one more node…
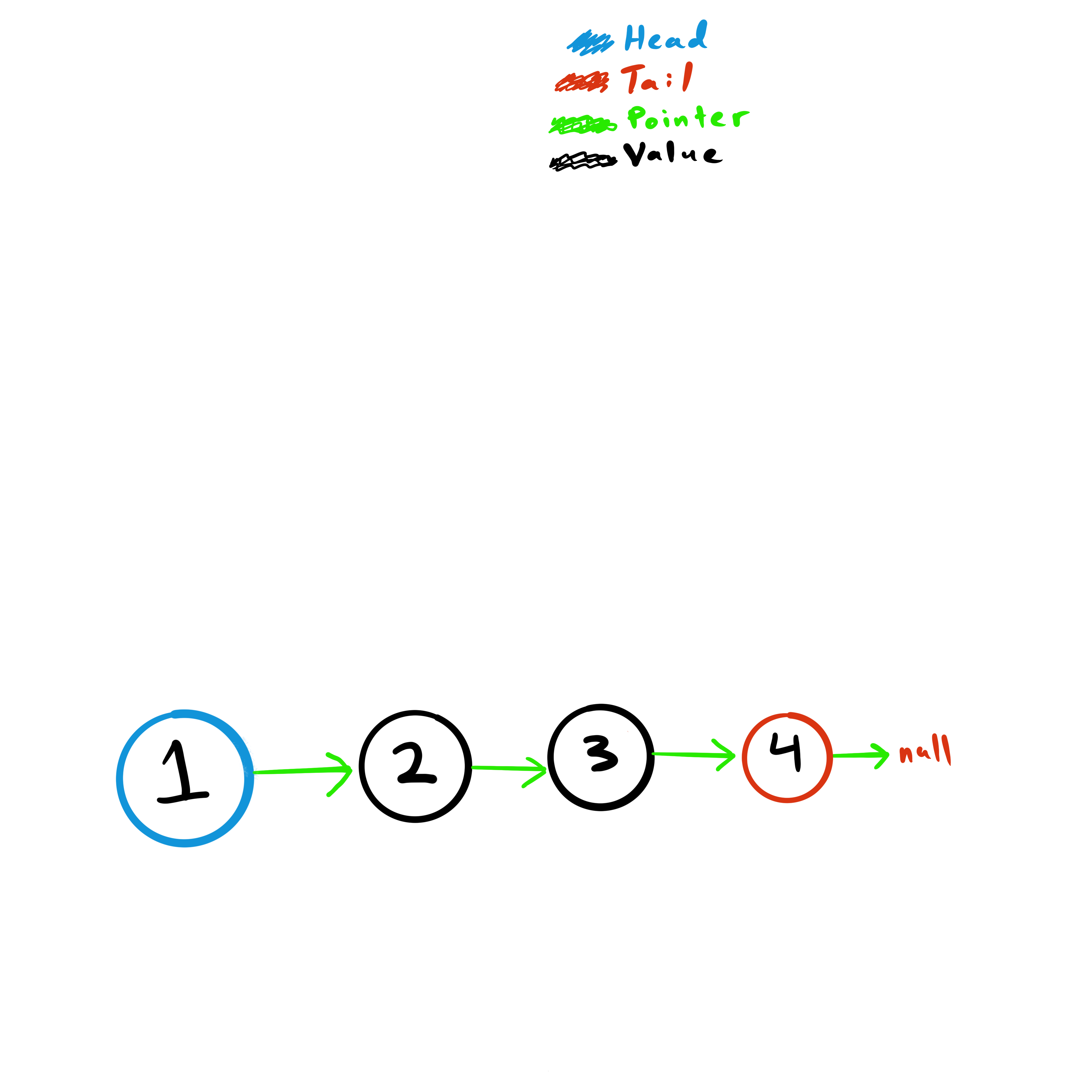
And here is the entire flow put together.
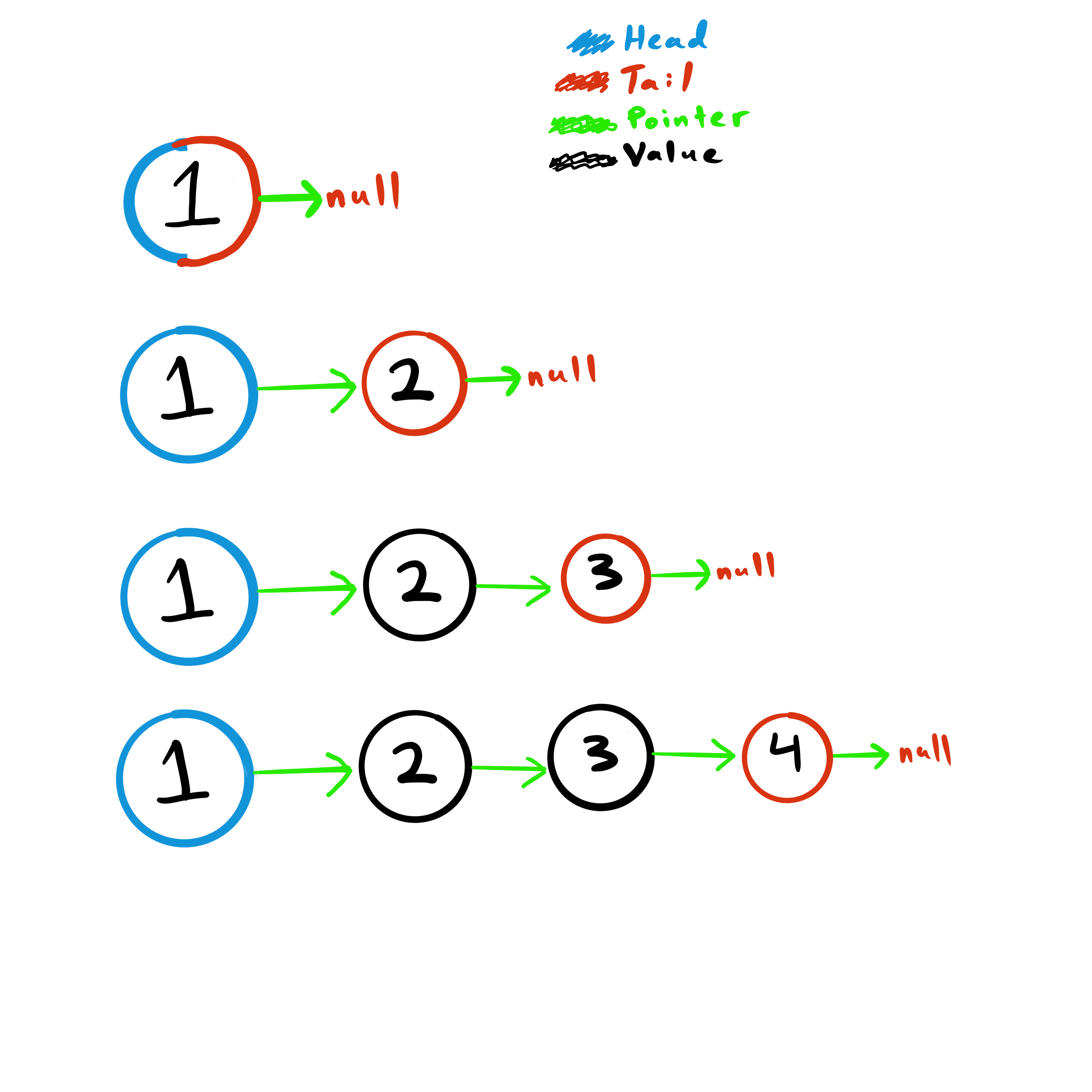
And that’s it! You just learned the basics of a singly-linked list data structure. Down below is an example of this in JavaScript.
class Node {
constructor(val) {
this.val = val;
this.next = null;
}
}
class SinglyLinkedList {
constructor() {
this.head = null;
this.tail = null;
this.length = 0;
}
// You would normally have a bunch of methods here that provide functionality for the list
append(val) {
const newNode = new Node(val);
if (!this.head) {
this.head = newNode;
} else {
this.tail.next = newNode;
}
this.tail = newNode;
this.length++;
}
}
Algorithms, what are they?
An algorithm can be described as a set of instructions you give to the computer, usually through code. We actually have an example of one in the code snippet above. While the Node and SinglyLinkedList classes represent core parts of the singly-linked list data structure, the append function is an example of an algorithm. Within the append function, we have instructions (code) that detail to the computer how we want it to behave. In this case, creating a new node and appending it to the end of our list. That’s mostly it, so when you hear someone mention the word algorithm in a programming context, they just mean the code/instructions that tell the computer to do something. Sticking to our data structure example where we created a human singly-linked list in an open field, the algorithm in that case could be a person hiding in a nearby bush telling each person when and where to go line up next in the list.
You may have also heard of something called Big O, I won’t dive into that topic here but it usually referenced in terms of time and space complexity. Aka, how long an algorithm takes to run in respect to it’s inputs and how much memory the algorithm takes up. I will likely do a deeper dive on these topics at a later point but wanted to mention it now as it is good to be aware that Big O is a thing. It is often the main driver on why we may choose one algorithm over another depending on the situation and constraints.